こんにちは、虎の穴ラボの山田です。
本記事は虎の穴ラボ Advent Calendar 2022の18日目の記事になります。
昨日17日目はNSSさんによる「Next.js でのWebサイト開発」が投稿されています。
明日19日目はT.K.さんによる「とらラボ雑談タイム「リモートコミュニケーション」の現在」が投稿される予定です。
こちらもぜひご覧ください。
はじめに
以前、こちらのブログに「監視ツールPrometheusのエクスポーターを自作してAWSのコスト監視を試してみました」という記事を投稿したところ、社内のメンバーから「Prometheusってなに?」といったことを聞かれました。
そこで今回は「はじめてのPrometheus」と題して、Prometheusの特徴の説明と、公式サイトのチュートリアルを実践してみたいと思います。
目次
Prometheusとは
Prometheusとは、2012年からSoundCloud社のエンジニアによって開発がはじめられたオープンソースのシステム監視ツールです。 Go言語で開発され、ソースコードはGitHub上で公開されています。 クラウドネイティブを推進する財団であるCloud Native Computing Foundationに、Kubernetesに続く2番目のホストプロジェクトとして2016年に参加し、2018年に卒業(graduated)しました。 prometheus.io github.com www.cncf.io
Prometheusの特徴
監視ツールであるPrometheusには以下のような特徴があります。
複数のコンポーネントで構成されるエコシステム
Prometheusによる監視システムは、コアとなるPrometheusサーバーと複数のオプションコンポーネントから構成されます。
Prometheusのコンポーネントには以下のようなものがあり、構成する監視システムによって導入を選択することができます。
- 一時的なジョブをサポートするためのPushgateway
- アラートを処理するAlertmanager
- 各種支援ツール
公式サイトでは以下のようなイラストで全体の構成を紹介しています。
 (公式サイトから引用した画像: https://prometheus.io/docs/introduction/overview/ より)
(公式サイトから引用した画像: https://prometheus.io/docs/introduction/overview/ より)
キー/値のペアで識別されるメトリック情報
Prometheusは基本的に、メトリック情報を時系列データとして保存します。 メトリック情報はメトリクス名とラベルと呼ばれるオプションの組み合わせをキーとした、キーと値のペアによって構成されます。

このメトリック情報にミリ秒精度のタイムスタンプが付与され保存されることで、多次元データモデルを構築しています。
多次元データモデルを活用するための柔軟なクエリ言語であるPromQL
PrometheusはPromQL(Prometheus Query Language)と呼ばれるクエリ言語を提供します。これを利用することで、ユーザーは収集された時系列データをリアルタイムに取得できます。
メトリクスの収集はHTTP経由のプル型
メトリクスの収集方法には大きく、サーバー側から対象に取りに行くプル型と、対象から送信されてくるのを待つプッシュ型に分かれます。 Prometheusではプル型が使用されています。 監視対象にはデータを収集するためのエージェントプログラムを導入しますが、Prometheusではこれを「エクスポーター」と呼びます。 エクスポーターは公式を含め多数作成されています。詳しくは公式ページを参照して下さい。
このエクスポーターに対し、Prometheusは定期的にプルを行うことでメトリクスを収集します。
プッシュ型への対応は中間ゲートウェイを介してサポート
Prometheusはプル型の監視ツールのため、主な監視対象は恒常的に動作するジョブになります。 バッチなどの一時的に動作するジョブに関しては、Pushgatewayという中間ゲートウェイを介してサポートしています。
監視対象の自動検出
Prometheusはプル型の監視ツールのため、監視対象のIPアドレスなどをサーバー側で認識しておく必要があります。 この監視対象の情報を設定ファイルに記述しておくことで静的に解決することもできますが、サービスディスカバリという監視対象を自動検出する仕組みで解決することもできるようになっています。
サービスディスカバリのためのモジュールも多数用意されています。詳しくは公式ページを参照して下さい。
ダッシュボードのサポート
メトリクスの視覚化には公式にGrafanaが勧められています。 これを利用してダッシュボードを作成することで、メトリクスの視覚化が行えます。 Prometheus自体にもグラフを表示する機能は備わっていますが、複数のグラフを同一画面に表示するなどは難しいため、ダッシュボードが必要な場合はGrafanaなどの外部ツールを利用することになります。
マイナーリリースサイクルが短期間
開発が活発で、マイナーリリースサイクルが6週間になっています。 また、長期サポートのためのLTS版も存在します。執筆時点(2022年12月)では2.37がLTS版です。
豊富なドキュメント
公式のドキュメントが整備されていて、内容が充実しています。 今回、このブログを書くにあたっても多くを参考にさせてもらっています。 ご使用の際はぜひご一読下さい。
Prometheus入門
ここからは公式サイトのチュートリアルを参考にして、PrometheusをローカルPCにインストールして動作を試します。
Prometheusは様々なOSとCPUアーキテクチャに対応していますが、本記事ではMacBook Proを使用していますので、コマンドなどは適宜読み替えて御覧ください。
環境
- macOS Monterey バージョン 12.6
- go バージョン 1.19.4
Prometheusのダウンロード
まずは公式ページのダウンロードサイトを確認し、最新版のリンク先を取得してダウンロードを行います。
https://prometheus.io/download/
ダウンロード後は展開して移動しておきます。
$ wget https://github.com/prometheus/prometheus/releases/download/v2.40.6/prometheus-2.40.6.darwin-amd64.tar.gz $ tar xvzf prometheus-2.40.6.darwin-amd64.tar.gz $ cd prometheus-2.40.6.darwin-amd64
自分自身を監視するようにPrometheusを構成
このままでも構わないのですが、この後の説明をスムーズにするため構成ファイルであるprometheus.ymlを編集します。
prometheus.ymlを開き、以下のように編集してください。
global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"]
プロメテウスの起動
以下のコマンドを実行しPrometheusを起動します。
$ ./prometheus --config.file=prometheus.yml
ターミナル上でPrometheusの起動が確認できたらブラウザでアクセスしてみます。
アクセスすると、以下のようが画面が確認できます。
Prometheusサーバーはエクスポーターのように自身のメトリクスを収集する機能も持っています。 以下にアクセスすることでそれが確認できます。
ここでエクスポーターがPrometheusに対して返す形式が確認できます。
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.4769e-05
go_gc_duration_seconds{quantile="0.25"} 7.5671e-05
go_gc_duration_seconds{quantile="0.5"} 0.000116323
go_gc_duration_seconds{quantile="0.75"} 0.000130677
go_gc_duration_seconds{quantile="1"} 0.000211978
go_gc_duration_seconds_sum 0.001534951
go_gc_duration_seconds_count 13
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 41
(以下、省略)
式ブラウザの使用
次に自身から収集したメトリクスを確認してみます。 まず画面上部の[Graph]をクリックするか、以下にアクセスしてグラフ画面に移動します。 移動後は[Table]タブが選択されていることを確認します。
表示されたら式の入力項目に以下のようなPromQLのクエリを入力し、[Execute]をクリックして実行します。
prometheus_target_interval_length_seconds
実行結果は以下のようになります。
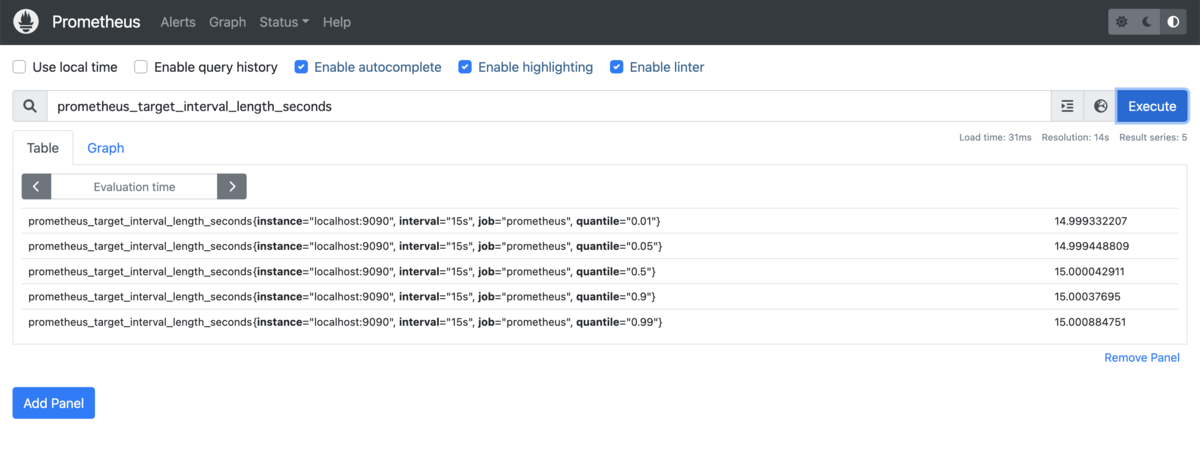
このクエリはスクレイプ時の実際の取得間隔の値を取得します。 表示されたメトリクスを見ると、4つのラベルが設定されているのが確認できます。 ここでラベルにあるintervalの値は設定した取得間隔です。これは前述のprometheus.ymlで設定した値が反映されています。 また、ラベルにあるquantileはパーセンタイルの値を示しています。
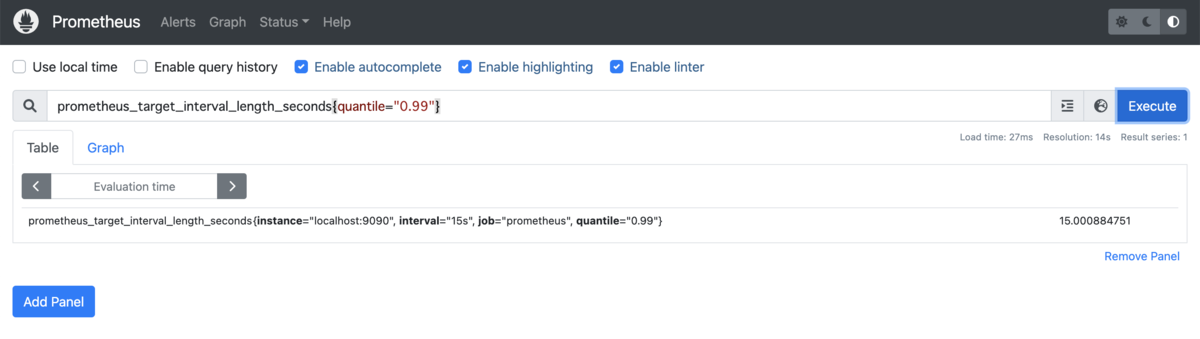
99パーセンタイルの値のみを取得する場合は、ラベルを指定したフィルタリングが行えます。 入力項目に以下のクエリを入力して[Execute]をクリックして実行します。
prometheus_target_interval_length_seconds{quantile="0.99"}
99パーセンタイルの値のみが表示されるのを確認できます。
グラフインターフェイスの使用
式ブラウザではPromQLのクエリ結果が表示されていました。
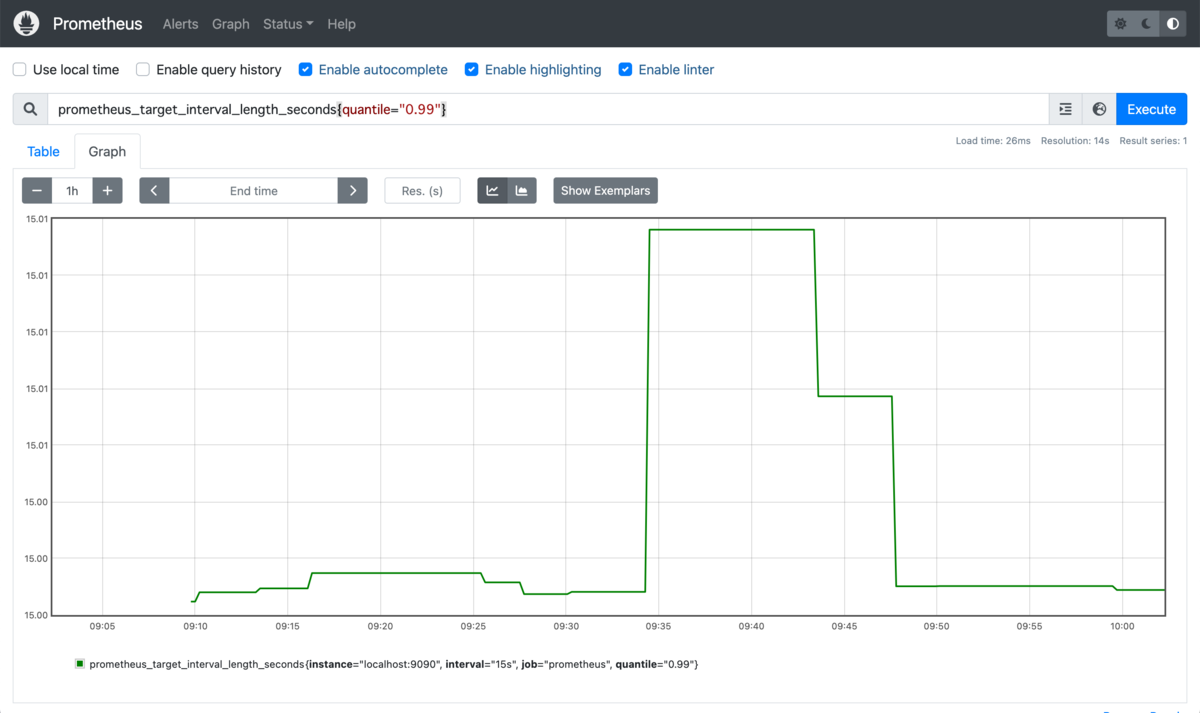
これをグラフ形式で表示したい場合は[Graph]タブを選択します。
先ほどの99パーセンタイルの値の変位が時系列のグラフで表示されます。
エクスポーターの導入
収集するメトリクスを追加するため、ローカルPCにエクスポーターを導入します。 ここではOSのメトリックを取得できるnode_exporterをダウンロードして起動します。
https://github.com/prometheus/node_exporter
Windows上で試す場合は、windows_exporterが利用できます。
https://github.com/prometheus-community/windows_exporter
Prometheusを実行中のターミナルとは別のターミナルを開き、以下を実行します。
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.darwin-amd64.tar.gz $ tar xvzf node_exporter-1.5.0.darwin-amd64.tar.gz $ cd node_exporter-1.5.0.darwin-amd64 $ ./node_exporter --web.listen-address 127.0.0.1:8080
一つ実行したら別のターミナルを二つ開き、ポート番号だけを変えて同様にnode_exporterを起動します。
$ ./node_exporter --web.listen-address 127.0.0.1:8081
$ ./node_exporter --web.listen-address 127.0.0.1:8082
これでローカルPC上でnode_exporterが三つ起動した状態になります。
エクスポーターの設定追加
次に起動した三つのnode_exporterを監視するようにPrometheusを構成します。
一旦、起動中のPrometheusを停止し、prometheus.ymlを以下のように編集します。
global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] - job_name: 'node' # Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 5s static_configs: - targets: ['localhost:8080', 'localhost:8081'] labels: group: 'production' - targets: ['localhost:8082'] labels: group: 'canary'
job_nameには任意の文字列が設定できます。ここでは対象がnode_exporterのため、job_nameにはnodeを設定しています。
編集完了後は先ほどと同様にPrometheusを起動します。
$ ./prometheus --config.file=prometheus.yml
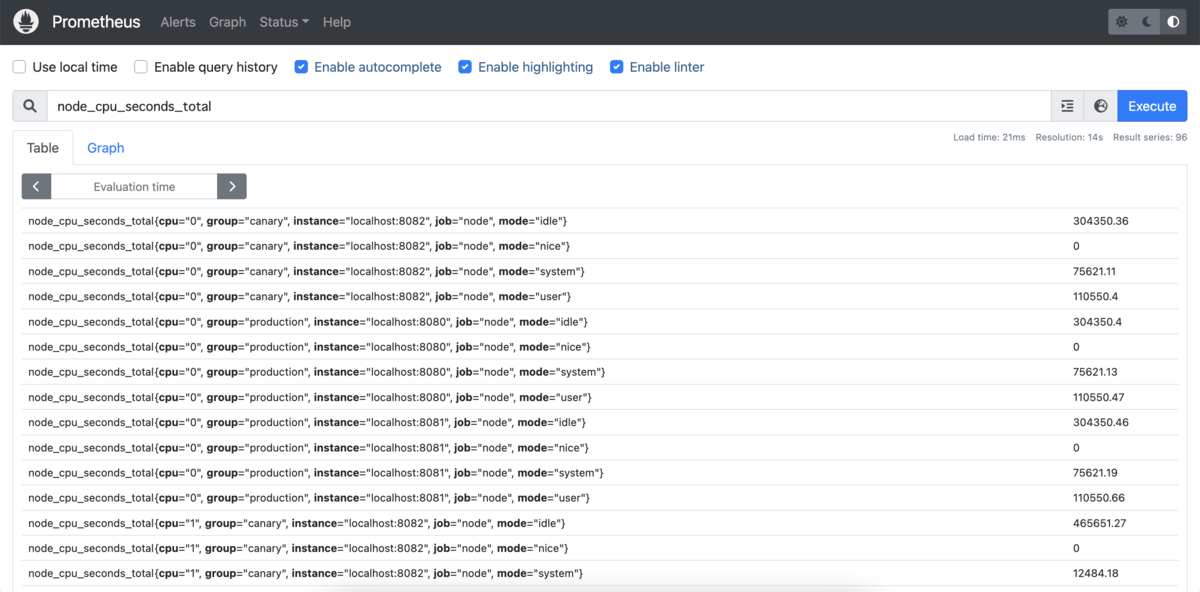
起動後は式ブラウザの画面でnode_cpu_seconds_totalを実行すると、node_exporterでOSの情報(CPUの情報)が取得できていることが確認できます。
また複数のエクスポーターからメトリクスを収集していること、設定によりグループ分けされていることなどが確認できます。
スクレイピングされたデータを集約するためのルールを追加
次にPromQLのrate関数を使って、5分間の期間で計測されたCPU時間の1秒あたりの増加率を以下のPromQLのクエリで取得してみます。
rate(node_cpu_seconds_total[5m])
実行結果は以下のようになります。

さらにavg関数を使い、指定したグループ内での平均値を取得するクエリを作成しメトリクスを取得してみます。
avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
実行すると、グループ単位での平均値が取得されているのが確認できます。

このクエリの取得値をメトリクスとして扱えるようにルールを構成します。
まずPrometheusを停止し、prometheus.rules.ymlという名前のファイルを作成し、以下のように編集します。
groups: - name: cpu-node rules: - record: job_instance_mode:node_cpu_seconds:avg_rate5m expr: avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
次にこのルールファイルを読み込むようにprometheus.ymlを以下のように編集します。
global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). rule_files: - 'prometheus.rules.yml' scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] - job_name: 'node' # Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 5s static_configs: - targets: ['localhost:8080', 'localhost:8081'] labels: group: 'production' - targets: ['localhost:8082'] labels: group: 'canary'
編集完了後は先ほどと同様にPrometheusを起動します。
$ ./prometheus --config.file=prometheus.yml
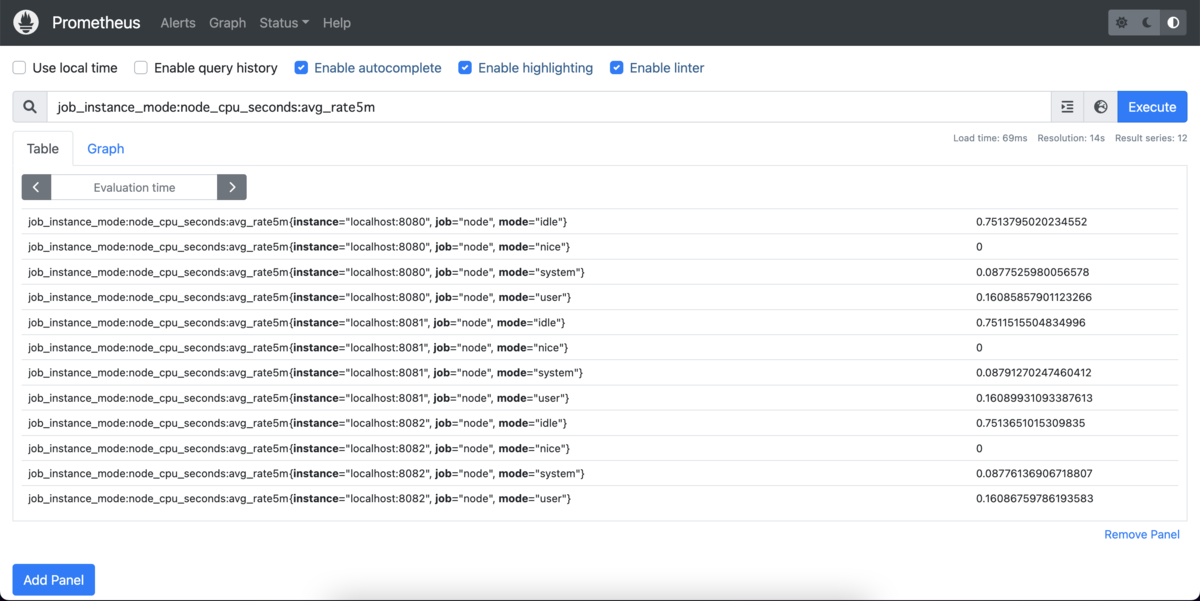
式ブラウザの画面で先ほどルールファイルのrecordに設定した文字列を入力して実行します。
job_instance_mode:node_cpu_seconds:avg_rate5m
設定したルールで新しいメトリクスを追加できたのが確認できます。
終わりに
今回はPrometheusの入門記事として、Prometheusの特徴と簡単な試用方法について紹介させていただきました。 業務で使用する場合は今回紹介していない設定も必要になりますが、公式ドキュメントの他にネット上の情報も多く、日本語の書籍も出版されていて、手を出しやすいツールだと思います。もし今回の記事で興味を持って頂けたなら幸いです。
参考書籍

P.S.
採用
虎の穴では一緒に働く仲間を募集中です!
この記事を読んで、興味を持っていただけた方はぜひ弊社の採用情報をご覧下さい。
yumenosora.co.jp
LINEスタンプ
エンジニア専用のメイドちゃんスタンプが完成しました!
「あの場面」で思わず使いたくなるようなスタンプから、日常で役立つスタンプを合計40個用意しました。
エンジニアの皆さん、エンジニアでない方もぜひスタンプを確認してみてください。
store.line.me
