この記事は、虎の穴ラボ Advent Calendar 2020の19個目の記事です。
昨日は、Adobe Animateを使ったアニメーションについてM.Mさんが、明日はDenoについておっくんの記事が投稿されます。ぜひこちらもご覧ください。
虎ラボブログに記事を書くのは久しぶりになります。
JUNE-JUNEです。 どんなエンジニアかは以下のインタビュー記事を読んでもらえればと思います。
今回書かせてもらうのは「GCP」に関するテクニックのひとつです。
サービスを成長させるにあたって、データベースの負荷対策というのは避けられない課題の1つですが、現在では技術も進歩して多くの方法があるかと思います。
そんな中、なにかしらの制限があり、特定の方法で負荷分散を行いたいという要件に応えるための方法を紹介します。

1. なぜ必要か
とあるサービス運営するにあたって、アクティブユーザ数が増え続けることに対するデータベースの負荷対策を考える必要がありました。
現在は問題ないものの、予め対策をしておかなければ「いつの間にかデータベースの負荷率があがっていた」という話は珍しくありません。
弊社の新規サービスの多くはRailsで作られており、Rails6では「マルチDB」の機能が搭載されています。
これを使えばプライマリDBとリードDBの切り替えが容易で負荷分散に役立ちますが、特定の処理に対して複数のリードDBを割り当てるというのは結構難しいです。
特に、アクセスが集中する処理やAPIに対しての複数台構成による負荷分散をする場合は、AWSのサービスとしては「AWSのAuroraを用いる」また手法としては「DNSラウンドロビンを用いる」という対策が考えられます。
今回はその「DNSラウンドロビン」をGCPの機能で簡単に実現するという内容になります。
2. CloudDNSとは
CroudDNSはGCPが提供するDNS機能で、その他のドメインサービスも同様の機能を搭載しています。
ただし、他のドメインサービスより優れているのは、ひとつのドメインに対して複数のIPを設定できることです。
これにより、「●●●.org」というドメインに「●●.11.123.0」と「●●.44.456.0」というIPをふたつ設定した場合、 「●●●.org」にアクセスしたらいずれかのIPにアクセスを自動的に振り分けてくれます。
また、自身のGCPプロジェクト内であれば限定公開やプライベートIPの設定なども可能で、セキュアなドメイン設定をすることも可能となります。
GCPで作られたサービスで複数データベースによる負荷分散をしたいのであれば、かなり有効な機能ではないかと思います。
3. 実践
では、実際にうまくいくのかを検証してみましょう。
3.1. ドメインを用意する
まずは何をするにしてもドメインの準備が必要です。
今回、個人でも使っているGoogleDomainsで取得しました。
だいたい年間で1,400円程度かかると思います。
今回の例では「●●●.org」のドメインを取得したものとします。
3.2. CloudSQLの準備
次に接続するCloudSQLを準備します。

後の検証で変化が分かりやすいように、プライマリDBにレプリカDBを1台作成しています。
また、GCPのプロジェクト内で完結するDNSを作成するため、プライベートIPの設定が必要となります。
3.3. CloudDNSの作成
お次はCloudDNSの作成です。
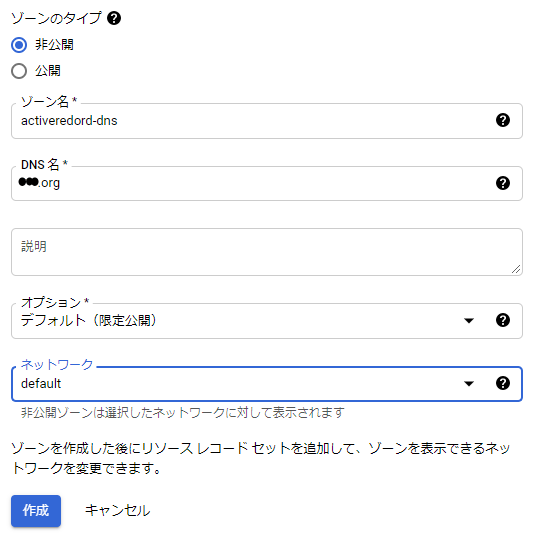
今回のようにGCP内でのデータベース振り分けを目的とするのであれば、「非公開」で作成します。
DNS名は取得したドメイン「●●●.org」を設定し、オプションなどはそのままで作成完了です。
3.4. NSレコードのレジストラ登録
今度は作成したCloudDNSの画面に書かれているNSレコードを、GoogleDomains側に設定します。 ※ドメインサービスによって詳細変わります

上図のように、カスタムネームサーバーを使用するにして、設定すればOKです。
3.5. AレコードへのIP追加
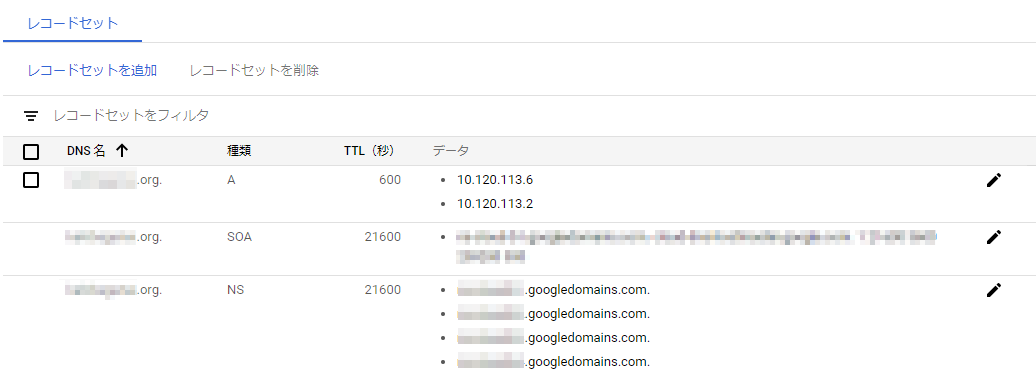
最後に、CloudDNS側でAレコードを「レコードセットを追加」で接続先IPアドレスを設定します。
このケースではプライマリDBとリードDBのプライマリIPを設定しています。
3.6 検証
最後に検証するにあたって、昔自分が作ったテスト用のリポジトリ「activerecord-practice」を使います。
同じVPCネットワーク内でVMインスタンスを立ち上げ、内部でアプリケーションを立ち上げます。
そして、Railsのconfig/database.ymlの設定を以下のようにします。
username: (設定したユーザ名) password: (設定したパスワード) port: 3306 host: ●●●.org
そしたらrails consoleを立ち上げ、実際のデータインサートがどうなるかを試します。
1回目のrails console起動
irb(main):019:0> Person.new.save
(0.6ms) BEGIN
Person Create (0.8ms) INSERT INTO `people` (`created_at`, `updated_at`) VALUES ('2020-12-14 00:04:23.234186', '2
020-12-14 00:04:23.234186')
(0.4ms) ROLLBACK
Traceback (most recent call last):
2: from (irb):18
1: from (irb):19:in `rescue in irb_binding'
ActiveRecord::StatementInvalid (Mysql2::Error: The MySQL server is running with the --super-read-only option so it
cannot execute this statement)
irb(main):020:0> exit
2回目のrails console起動
irb(main):001:0> Person.new.save
(10.4ms) SET @@SESSION.sql_mode = CONCAT(CONCAT(@@sql_mode, ',STRICT_ALL_TABLES'), ',NO_AUTO_VALUE_ON_ZERO'),
@@SESSION.sql_auto_is_null = 0, @@SESSION.wait_timeout = 2147483
(2.3ms) BEGIN
Person Create (21.0ms) INSERT INTO `people` (`created_at`, `updated_at`) VALUES ('2020-12-14 00:04:35.748650', '
2020-12-14 00:04:35.748650')
(8.6ms) COMMIT
=> true
irb(main):002:0> Person.new.save
(6.8ms) BEGIN
Person Create (4.8ms) INSERT INTO `people` (`created_at`, `updated_at`) VALUES ('2020-12-14 00:04:47.140646', '2
020-12-14 00:04:47.140646')
(7.9ms) COMMIT
=> true
irb(main):020:0> exit
3回目のrails console起動
irb(main):019:0> Person.new.save
(0.6ms) BEGIN
Person Create (0.8ms) INSERT INTO `people` (`created_at`, `updated_at`) VALUES ('2020-12-14 00:04:23.234186', '2
020-12-14 00:04:23.234186')
(0.4ms) ROLLBACK
Traceback (most recent call last):
2: from (irb):18
1: from (irb):19:in `rescue in irb_binding'
ActiveRecord::StatementInvalid (Mysql2::Error: The MySQL server is running with the --super-read-only option so it
cannot execute this statement)
irb(main):020:0> exit
おわかりでしょうか。 ランダムにプライマリDBとリードDBに接続し、1回目と3回目はリードDBに接続しインサートが出来ずエラーがでています。
Railsはコネクションプールを貼っているので同じコンソールの中だとそれぞれのデータベース接続を保持し続けており、 再接続するとちゃんとランダムで振り分けられるようです。
本来の使い方としては異なるリードDBでの振り分けですが、プライマリとリードに接続した今回の検証で、実際に複数のデータベースへ接続が振り分けられることがわかりました。
また、速度の検証も行いましたが、読み込み書き込み共にCloudDNSの場合の遅延などもなく、パフォーマンスも問題なさそうです。
4. おわりに
こちらの手法に関しては、業務での取引先の方からその存在をお聞きしたのですが、 実際にやってみるとかなりスムーズに実現できたことに驚きです。
GCPはいつの間にかかなり便利な機能がリリースされているということが多いので、今後もこういった新機能のウォッチは続けていきたいですね。
P.S.
あとから気づいたのですが、実はドメインは用意しなくても内部ドメインとして認識されるので不要でした。
●●●.orgの部分をGoogleDomainsで取得していなくてもCloudDNSで設定すれば、 内部ネットワーク内では●●●.orgを認識してくれます。
虎の穴ラボではいくつかのオンラインイベントを企画しております。是非ご参加ください!!
TORA LAB Management & Leader Meetup
12/23(金) 19:30からとらのあなが運営している「とらのあな通販」と「Fantia」の開発の魅力を発表し、参加いただいた方の気になる点やご質問に答えるイベントとなっています。 yumenosora.connpass.com
その他採用情報
虎の穴ラボでの開発に少しでも興味を持っていただけた方は、採用説明会やカジュアル面談という場でもっと深くお話しすることもできます。ぜひお気軽に申し込みいただければ幸いです。 カジュアル面談では虎の穴ラボのエンジニアが、開発プロセスの内容であったり、「今期何見ました?」といったオタクトークから業務の話まで何でもお応えします。 カジュアル面談や採用情報はこちらをご確認ください。 yumenosora.co.jp
