こんにちは。
虎の穴ラボ株式会社の iwady です。
皆さん、Python してますか?
今回は Python に直接関連するお話ではないのですが、
私がこれまで開発メンバーおよびマネージャーとして携わってきた「機械学習プロジェクト」について振り返ってみたいと思います。
プロジェクト全体の流れや、私個人が現場で感じた「注意すべき点」を、開発とマネジメント両方の視点からお話しします。

1. 機械学習プロジェクトとは
本記事では、「データを用いて自動で学習を行い、そのデータの特徴やパターンを活用したシステムを開発する案件」を機械学習プロジェクトと定義します。
具体的には、既存のデータから協調フィルタリングを用いて商品をおすすめしたり、画像から関連キーワードを予測したりといった機能です。
従来の明示的なルールベースや SQL、正規表現、単純な自動化だけでは実現が困難な課題を、データの力で解決する事を目指すプロジェクトです。
2. 携わってきた案件たち
私がこれまで、運用フェーズ以外で深く携わった機械学習案件は主に3つあります。
| 案件名 | 役割 | 概要・使用技術 |
|---|---|---|
| ① コンテンツ推薦システム | 実装・モデル開発 | 10年以上前のフルスクラッチ開発。機械学習系のクラウドサービスがない時代に、データ前準備からデプロイまで全てマニュアルで構築。 |
| ② 画像タグ予測システム | 実装・マネジメント | 作品画像から「ファンタジー」等のタグを自動提案。モデル更新パイプラインの実装や、ステークホルダーとの調整・進捗管理を担当。 |
| ③ コンテンツ推薦システム | 実装・モデル開発 | 2025年11月リリース。BigQueryMLを活用。コスト最適化や精度向上のためのハイパーパラメータチューニングなど、エンジニアリングとDSの両面で対応。 |
このように振り返ってみると、この10年ちょっとで機械学習を取り巻く開発環境は劇的に変化したように感じます。
1つ目の案件当時は、モデルを一つデプロイするのにもインフラの構築からライブラリの依存関係解消まで、泥臭く進める必要がありました。
しかし、現在は各種クラウドのマネージドサービスを活用することで、「モデルをどう作るか」よりも「データをどう活用し、どうビジネス価値に繋げるか」という、より本質的な課題に集中できるようになったと思います。
一方で、技術スタックがどれだけ進歩しても変わらない難しさもありますね。
それは、「機械学習プロジェクトの特有の不確実性」と「ビジネス」との折り合いをどうつけるかという点です。
次の章では、この点も交えつつ、機械学習プロジェクトの大まかな開発フローと、各フェーズでの注意点について整理していきたいと思います。
3. 機械学習案件の開発の流れ
私が経験してきた機械学習プロジェクトの開発フローを整理すると、概ね以下のような流れになります。
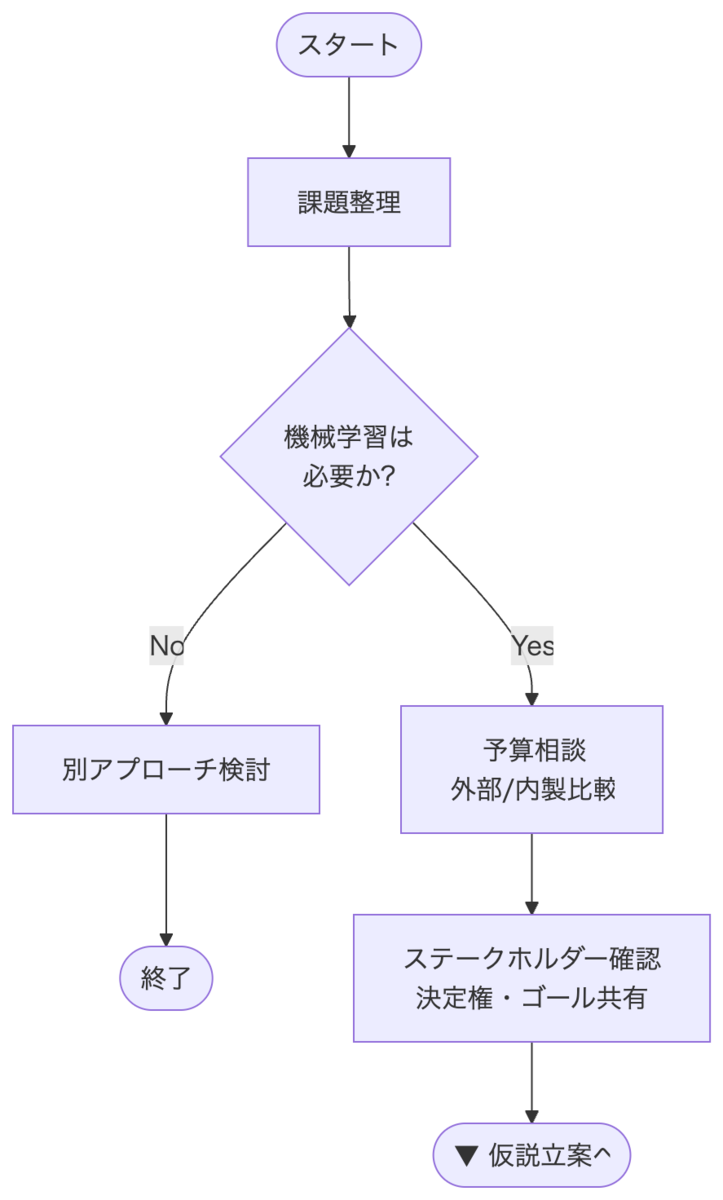
3-1. 課題の整理とプロジェクト方針策定
まず、課題の整理になります。
「解決したい課題に対して、本当に機械学習が必要なのか」をしっかりと検討する必要があります。
AI や機械学習を使うこと自体が目的化しないよう、単純な自動化・ルールベースなどで解決できるならそちらも検討します。
次に予算との相談を行い、外部サービス (SaaSやAPIなど) を利用するか、内製するかを整理・比較します。
そして、重要なのがステークホルダーの確認です。
プロジェクトの参加者全員で誰が決定権を持っているのかを初期段階で明確にし、プロジェクトのゴールや評価について共有しておく必要があります。
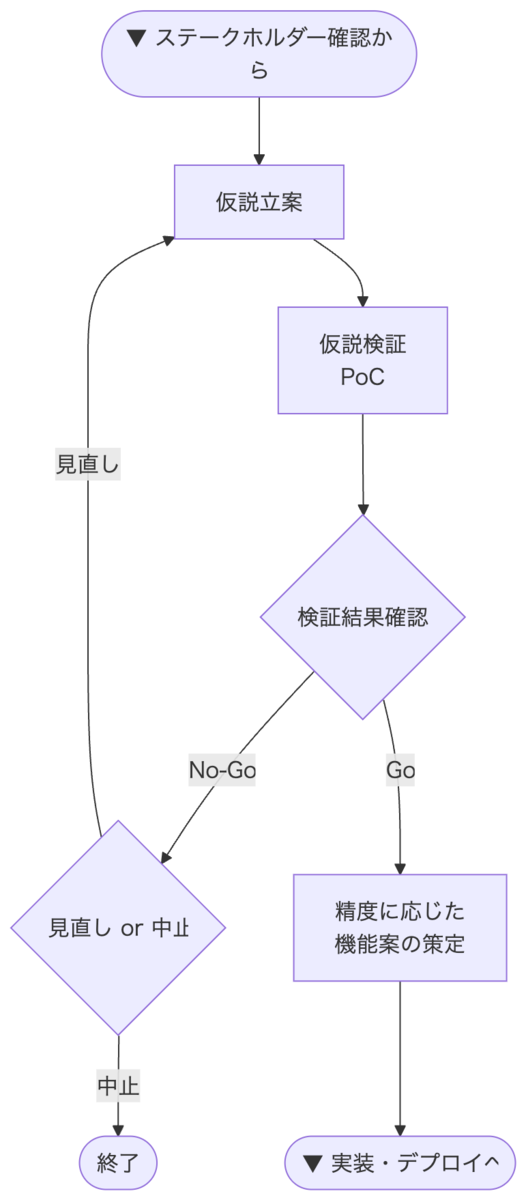
3-2. 仮説立案〜検証(PoC)
次に、仮説を立案します。
どのデータを使い、どういった説明変数や特徴量を選定するかを決めますが、初期段階では「それらしさ」や感覚的なもので構わないと思います。
最初から完璧を目指さず、仮説検証の中でキャリブレーションしていくスタンスで進めると良いかと思います。
続いて、仮説検証(PoC)です。
ここが機械学習プロジェクトで最も特徴的かつ、時間がかかるフェーズです。
データの前処理などはもちろん、既存のモデルがある場合は転移学習なども含めて視野に入れ、実際にモデルを作成し検証を行います。
この検証結果をもって、このまま進めるか(Go/No-Go)をステークホルダーと調整します。
自身の経験上、仮説検証とステークホルダーとの調整は何回も往復する(または並行で進む)ことがありますので、ここは時間や予算と相談しながらの判断になります。
Go の確度が高い場合、この段階で運用(モデル更新やデータ更新、A/Bテストの方法など)についても解像度を高めておくと、後の社会実装時の設計がスムーズになります。
また、Go は出たものの、社会実装の段階で「やはりモデルの精度が芳しくない」という評価が出てしまうことも、開発現場では多々あるかと思います。
「PoC時点ではそこそこの精度だが、実装フェーズと並行してモデル精度向上の期間も確保しているため、リリースまでにもっと良くなるはずだ」という改善への期待を込めて、ステークホルダーがGoサインを出すケースなども考えられますよね。
個人的には、仮説検証の段階でモデルのオフライン評価の共有やステークホルダーによる定性評価を行い、期待値のすり合わせをしっかり行っても、そういったケースを完全に回避することは不可能だと思います。
そのため、「精度が理想に届かなかった場合にどうするか」をこの段階で想定しておくと、実装フェーズで慌てずに済むかと思います。
例えば、第2章で紹介した私が担当した2件目の案件である入力画像からタグを予測するシステムで考えると、以下のような段階的な機能提供が考えられます。
• 精度が高い場合(理想): タグ付与の自動処理をデフォルトとし、ユーザーは最終確認(+好みのタグを追加)するだけの機能にする。
• 精度がそこそこの場合(現実的ライン): 自動付与はせず「タグのサジェスト(提案)」に留め、ユーザーが候補の中から選ぶ機能にする。
• 精度が低い場合(撤退視野のライン): 機能自体をリリースしない、または入力補助程度の役割に留める。
予測精度に応じて「機能がどう振る舞うか」のケースをあらかじめ幾つか想定し、機能の落としどころを用意しておくと良いと思います。
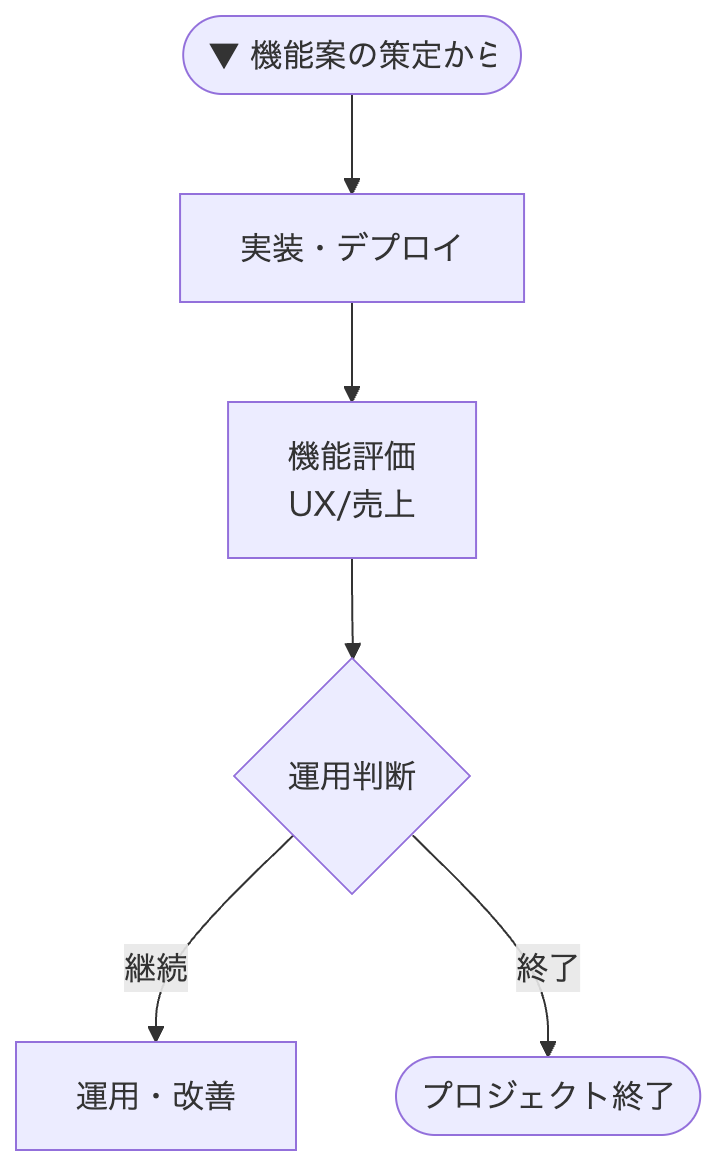
3-3. 社会実装・デプロイ
仮説検証でGoが出たら、いよいよ実装フェーズです。
自身の経験上、このフェーズでは「アプリケーションとしての社会実装」と「モデル精度の向上作業」が並行して進むことが多いです。
ここで最も警戒すべきなのが、「モデル精度の向上」という沼です。精度向上には際限がありません。
「あと少しパラメータをいじれば良くなるかも」「データの前処理を変えれば...」とこだわっていると、いつまで経ってもリリースできない事態に陥ります。
モデル精度の向上にプロジェクト全体が引っ張られないよう、時間や予算などの明確な指標に基づいてプロジェクトを進めていく必要があります。
機械学習プロジェクトは、通常の開発にはない PoC の工程や、GPU/TPU などの高価なリソースを必要とする「コストがかさむ」性質を持っています。
可能な限り早く機能としての価値を提供するという意識が大切かと感じました。
運用についても、MLOpsを専門とするチームが行うのか、サービスを管掌するチームのエンジニアが運用するのかなど、忘れずに考慮しておきたいですね。
3-4. 評価・運用
最後にデプロイし、3-1 課題の整理とプロジェクト方針策定で決めた機能としての評価を行います。
これは最終的なモデルの精度評価だけではなく、ビジネス的な価値や機能としての有用性などを含む形になります。
「UXが向上したか」あるいは「売上に寄与しているか」などのビジネス指標に加え、
「今後の機械学習開発の基盤となっているか」あるいは「データやノウハウの蓄積に有用か」などの開発指標も含めて多角的に評価します。
その後は、改善や運用フェーズに入るか、リリースして完結ならそこでプロジェクト終了となります。
3-5. フロー図
図にすると以下のような形になります。
長くなりましたので、3パートに分けてフローチャートにしています。
課題整理・プロジェクト方針など大枠を決め...
仮説検証で機能としての実現可能性を探り...
社会実装を行い、評価・運用するという形になります。
4. まとめ
今回は、私が担当してきた機械学習関連の案件について振り返ってみました。
最後に、これらの経験を通じて感じた、機械学習プロジェクトの「落とし穴」に落ちないポイントをまとめようと思います。
4-1. その課題、解決するのに本当に機械学習が必要ですか?
最も陥りやすい罠は、「AI・機械学習を使うこと」自体が目的化してしまうことです。
「AI・機械学習で何かやりたい」という動機だけで始まると、課題の温度感が低かったり、外部のSaaSを使えば済むところに過剰な工数をかけたりしてしまいがちです。
技術選定の際は、解決したい課題に対して機械学習が最適解なのかを冷静に見極める必要があります。
4-2.「精度の沼」にハマらないためのリリース計画
機械学習モデルの精度向上には際限がなく、まさに「沼」です。
「精度が基準を超えるまでリリースしない」といった目標を掲げると、プロジェクトはいつまでも終わりません。
期間や予算に明確な制限を設け、精度に応じた段階的なリリース計画(精度が低ければサジェストに留めるなど)を事前に策定しておくことが重要です。
4-3.不確実性を共有し、早期の収益化を目指す
機械学習には「やってみないとわからない」不確実性が伴います。
ステークホルダーとは「モデルの精度次第で機能やUIが変わる可能性がある」というリスクを事前に共有し、認識のズレを防ぎましょう。
早い段階で収益化(ROI)を意識した開発を行うことが、プロジェクトを健全に進める鍵となります。
5. おわりに
機械学習は強力な武器ですが、コストも高く、使い所が難しい技術です。
ただ、技術だけでなく、ビジネスなど多角的な視野が求められる本当に面白い分野だと思います。
この記事が、これから機械学習プロジェクトに挑む方や、
現在進行形で奮闘されている方にとって「転ばぬ先の杖」となれば幸いです。
最後に、あくまで本記事は私の個人的な経験に基づく振り返りになりますので、
各現場・プロジェクトで進め方や留意点が異なる可能性はあります事を付記いたします。
採用情報
虎の穴では一緒に働く仲間を募集中です!
この記事を読んで、興味を持っていただけた方はぜひ弊社の採用情報をご覧下さい。
カジュアル面談やエンジニア向けイベントも随時開催中です。ぜひチェックしてみてください。
