 こんにちは! 虎の穴ラボのA.Mです。
こんにちは! 虎の穴ラボのA.Mです。
この記事は夏の連載企画の10日目の記事です。
前回はS.Aさんによる「GPT-4o の画像解析でレシートを読み取る bot を作ってみた」が投稿されました。
OpenAIのChatGPTは普段からよく使っていますが、昨年末から話題になっているGoogleの生成AIであるGeminiはまだ触ったことがなかったので、今回はGeminiのAPIをいろいろ触ってみたいと思います。
Geminiについて
Geminiは、Googleが開発しているマルチモーダル生成AIです。 マルチモーダルは、複数の形式や手段を組み合わせることを意味しており、Geminiは入力にテキストデータだけでなく、画像・音声・動画といった異なる種類のデータを組み合わせて使用できるという特徴があります。
Gemini APIで使えるモデル
Gemini APIでは、以下のようなさまざまなモデルが使えます。
※公式ドキュメントより引用
| モデル バリアント | 入力 | 出力 | 最適な用途 |
|---|---|---|---|
| Gemini 1.5 Pro(プレビュー) | 音声、画像、動画、テキスト | テキスト | 推論タスクには、コードとテキストの生成、テキスト編集、問題解決、データの抽出と生成が含まれますが、これらに限定されません。 |
| Gemini 1.5 Flash(プレビュー) | 音声、画像、動画、テキスト | テキスト | さまざまなタスクで高速かつ汎用性の高いパフォーマンスを実現 |
| Gemini 1.0 Pro | テキスト | テキスト | 自然言語タスク、マルチターン テキストとコードチャット、コード生成 |
| Gemini 1.0 Pro Vision | 画像、動画、テキスト | テキスト | 画像の説明の生成や画像内のオブジェクトの識別など、視覚関連のタスク向けに最適化されたパフォーマンス |
| テキスト エンベディング | テキスト | テキスト エンベディング | 最大 2,048 個のトークンのテキストに対して最大 768 次元の弾力性のあるテキスト エンベディングを生成します。 |
| エンベディング | テキスト | テキスト エンベディング | 最大 2,048 トークンのテキストに対して 768 次元のテキスト エンベディングを生成します。 |
| AQA | テキスト | テキスト | 指定されたテキストに対してアトリビューション付きの質問応答関連のタスクを実行する |
現状、レート制限はあるものの、ちょっと試すくらいなら無料で使えるようです。(2024年6月時点)
詳細は公式ページをご確認ください。
Gemini API の料金 | Google for Developers
Gemini API を触ってみる
APIキーの発行
まずはAPIキーを発行します。
「Google AI Studio」を開きます。
Google AI Studio | Gemini API | Google for Developers
続いて、サイドメニューの「Get API Key」ボタンを押します。
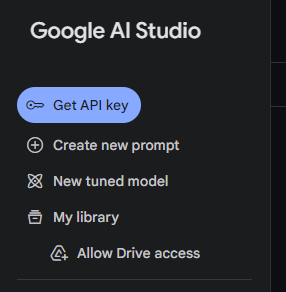
「APIキーを作成」ボタンを押します。
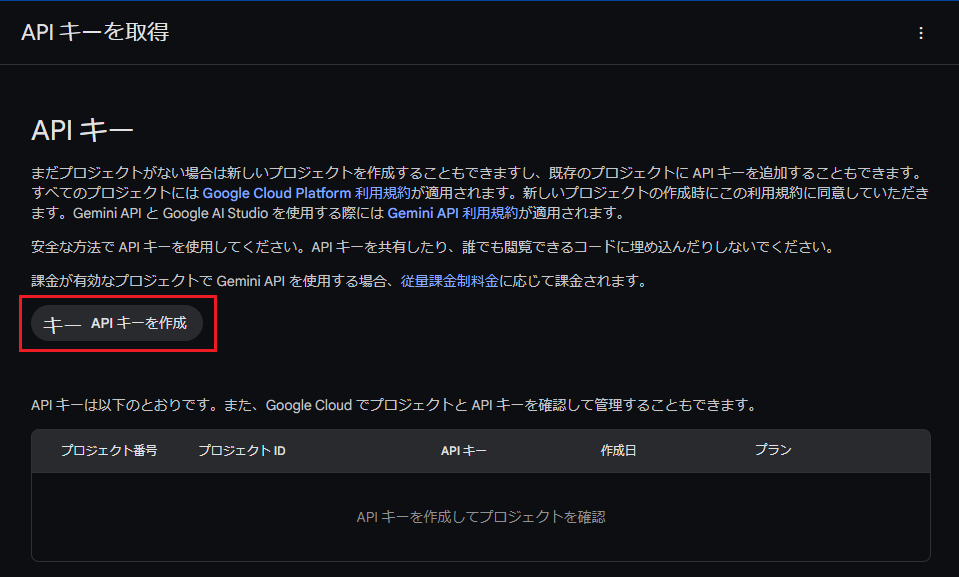
以下のようなダイアログが表示された場合は確認の上「OK」を押します。

「新しいプロジェクトでAPIキーを作成」を選択します。既存のGoogle Cloudプロジェクトがある場合はそちらを選択してもOKです。
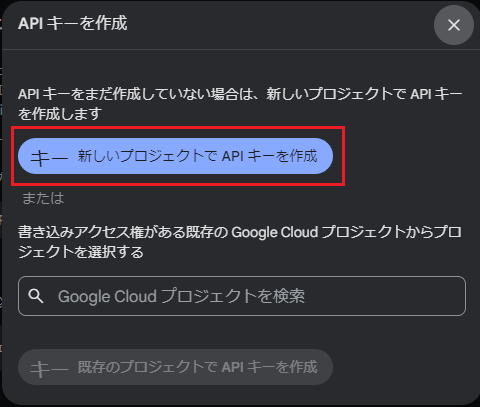
作成された「APIキー」をコピーしておきます。

一度画面をリロードすると、下部にテスト用のcurlコマンドが表示されます。
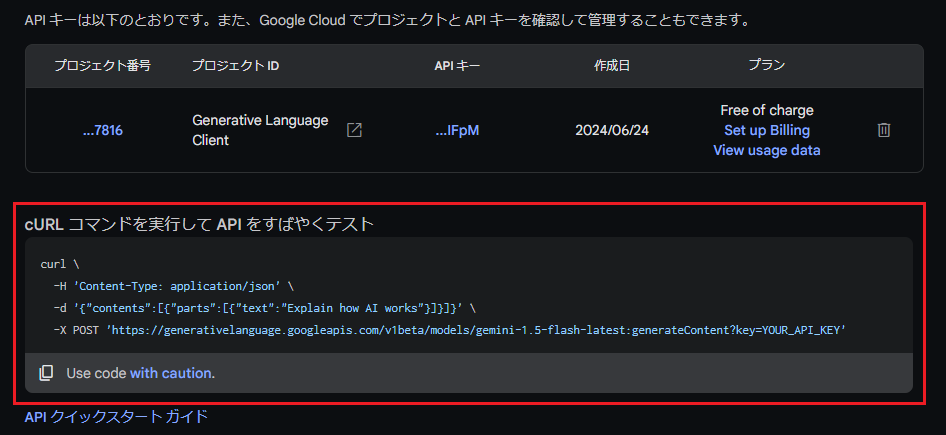
APIキーを指定して実行してみます。
(YOUR_API_KEYは、先ほどコピーしたAPIキーに置き換えてください)
APIのエンドポイントから、モデルは「Gemini 1.5 Flash」の最新版が指定されているのが分かりますね。
curl \ -H 'Content-Type: application/json' \ -d '{"contents":[{"parts":[{"text":"Explain how AI works"}]}]}' \ -X POST 'https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent?key=YOUR_API_KEY'
以下のようなレスポンスが返ってきていればOKです。
{ "candidates": [ { "content": { "parts": [ { "text": "## How AI Works: A Simplified Explanation\n\nArtificial intelligence (AI) is essentially the ability of a computer to perform tasks that typically require human intelligence. It's a vast field, but at its core, AI works by:\n\n**1. Learning from Data:**\n - AI systems learn from massive amounts of data, like text, images, or sound. This data is used to train the AI model.\n - Think of it like teaching a child. You show them pictures of animals and tell them their names. Eventually, they learn to recognize different animals.\n\n**2. Using Algorithms:**\n - AI uses algorithms (sets of instructions) to analyze and understand the data. These algorithms can be complex, but their basic goal is to find patterns and relationships within the data.\n - This is like the child using the information they learned to identify new animals they haven't seen before.\n\n**3. Making Predictions and Decisions:**\n - Based on the patterns and relationships found in the data, AI systems can make predictions and decisions. This can involve things like:\n - Classifying objects in images\n - Translating text into different languages\n - Generating creative content\n - Providing personalized recommendations\n - The child, after learning about animals, can now tell you what kind of animal they see in a new picture.\n\n**Different Types of AI:**\n\n- **Machine Learning:** This involves algorithms that learn from data without being explicitly programmed. For example, a machine learning system could learn to identify spam emails without being told what spam looks like.\n- **Deep Learning:** This is a type of machine learning that uses complex artificial neural networks inspired by the structure of the human brain. These networks can handle more complex tasks, like image recognition and natural language processing.\n- **Expert Systems:** These are AI systems designed to mimic the knowledge and decision-making abilities of human experts. They are often used in fields like medicine and finance.\n\n**In simpler terms:**\n\nThink of AI as a super-powered computer that can learn and solve problems like humans do. It's not a single thing, but a collection of techniques and technologies that allow machines to do amazing things!\n\n**Important Note:** AI is still under development, and there's a lot we don't know yet. But it's already transforming many industries, and its potential is truly exciting. \n" } ], "role": "model" }, "finishReason": "STOP", "index": 0, "safetyRatings": [ { "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HATE_SPEECH", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HARASSMENT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_DANGEROUS_CONTENT", "probability": "NEGLIGIBLE" } ] } ], "usageMetadata": { "promptTokenCount": 4, "candidatesTokenCount": 493, "totalTokenCount": 497 } }
ちなみに、APIキーが間違っている場合は以下のようなエラーが返ってきます。
{ "error": { "code": 400, "message": "API key not valid. Please pass a valid API key.", "status": "INVALID_ARGUMENT", "details": [ { "@type": "type.googleapis.com/google.rpc.ErrorInfo", "reason": "API_KEY_INVALID", "domain": "googleapis.com", "metadata": { "service": "generativelanguage.googleapis.com" } } ] } }
簡単なプロンプトを入力してみる
まずは自己紹介をしてもらいましょう。
(YOUR_API_KEYは、先ほどコピーしたAPIキーに置き換えてください)
API_KEY="YOUR_API_KEY" curl \ -H 'Content-Type: application/json' \ -d '{"contents":[{"parts":[{"text":"自己紹介をしてください。200文字以内で回答してください。"}]}]}' \ -X POST 'https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-latest:generateContent?key=${API_KEY}'
レスポンスとして以下のような内容が返ってきました。
※candidates.content.parts.textの内容を抜粋
こんにちは!私はGoogleによって訓練された、大規模言語モデルです。膨大なテキストデータから学習し、様々なタスクを実行できます。例えば、文章の生成、翻訳、要約、質問への回答などです。常に学習を続けており、より賢く役に立つ存在を目指しています。何か質問があれば、遠慮なく聞いてください!
画像を読み込ませてみる
次に、画像を読み込ませてみます。
使う画像はこちらのメイドちゃん。

この画像をGeminiに渡して、説明をしてもらいます。
# 画像データはbase64エンコードして渡す IMAGE_DATA=$(base64 42_toralabevent.png) curl https://generativelanguage.googleapis.com/v1/models/gemini-1.5-flash:generateContent?key=${API_KEY} \ -H 'Content-Type: application/json' \ -X POST \ -d '{ "contents":[ { "parts":[ {"text": "画像を説明してください。日本語で回答してください。"}, { "inlineData": { "mimeType": "image/png", "data": "'${IMAGE_DATA}'" } } ] } ] }'
実行結果は以下のようになります。
※candidates.content.parts.textの内容を抜粋
画像には、紫色の髪をした女の子が、ピンク色のテーブルの前に立っています。テーブルの上には、絵の具のパレットが描かれた看板と、何枚もの紙が積み重ねられたものが置かれています。女の子は、笑顔で紙を手に持ち、テーブルの看板に「とらぶ!」と書かれた文字を指さしています。女の子の隣には、赤い旗が立てられており、「とらぶ」と書かれた文字が書かれています。背景は白です。全体的に、女の子が何か商品を販売している様子が描かれた、かわいらしいイラストです。
手書き風の文字はさすがに正しく読み取れなかったようで、「とらラボ!」が「とらぶ」になっていますが、説明自体はだいたい合ってそうです。
レスポンスのJSON形式を指定してみる
次のように、generationConfigにresponse_mime_typeを指定することで、レスポンスの形式をJSONに指定できます。
curl https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key=$API_KEY \ -H 'Content-Type: application/json' \ -X POST \ -d '{ "contents": [ { "parts": [ { "text": "カレーに使われる代表的なスパイスを5つ挙げてください。次のJSONスキーマで回答してください。 schema:\n\n Spice = {\"spice_name\": str, \"explanation\": str}\n\nReturn a `list[Recipe]`\n " } ] } ], "generationConfig": { "response_mime_type": "application/json" } }'
レスポンスは以下の通りです。
"candidates": [ { "content": { "parts": [ { "text": "[{\"spice_name\": \"ターメリック\", \"explanation\": \"黄色い粉末で、カレーのベースとなるスパイス。独特の風味と色合いを与えます。抗炎症作用も期待できます。\"}, {\"spice_name\": \"コリアンダー\", \"explanation\": \"独特の香りと苦味を持つスパイス。カレーに深みと複雑さを加えます。消化促進作用も期待できます。\"}, {\"spice_name\": \"クミン\", \"explanation\": \"ナッツのような風味を持つスパイス。カレーに暖かさと香ばしさを加えます。消化促進作用も期待できます。\"}, {\"spice_name\": \"チリペッパー\", \"explanation\": \"辛味を加えるスパイス。種類によって辛さの度合いが異なります。食欲増進作用も期待できます。\"}, {\"spice_name\": \"ガラムマサラ\", \"explanation\": \"複数のスパイスをブレンドしたものです。カレーに複雑な風味と香りを加えます。一般的に、カレー粉にはガラムマサラが含まれています。\"}]\n" } ], "role": "model" }, "finishReason": "STOP", "index": 0, "safetyRatings": [ { "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HATE_SPEECH", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_HARASSMENT", "probability": "NEGLIGIBLE" }, { "category": "HARM_CATEGORY_DANGEROUS_CONTENT", "probability": "NEGLIGIBLE" } ] } ], "usageMetadata": { "promptTokenCount": 50, "candidatesTokenCount": 216, "totalTokenCount": 266 } }
JSONスキーマの部分を整形すると、以下のようになります。
指定した通りの形式で出力されていますね。
[ { "spice_name": "ターメリック", "explanation": "黄色い粉末で、カレーのベースとなるスパイス。独特の風味と色合いを与えます。抗炎症作用も期待できます。" }, { "spice_name": "コリアンダー", "explanation": "独特の香りと苦味を持つスパイス。カレーに深みと複雑さを加えます。消化促進作用も期待できます。" }, { "spice_name": "クミン", "explanation": "ナッツのような風味を持つスパイス。カレーに暖かさと香ばしさを加えます。消化促進作用も期待できます。" }, { "spice_name": "チリペッパー", "explanation": "辛味を加えるスパイス。種類によって辛さの度合いが異なります。食欲増進作用も期待できます。" }, { "spice_name": "ガラムマサラ", "explanation": "複数のスパイスをブレンドしたものです。カレーに複雑な風味と香りを加えます。一般的に、カレー粉にはガラムマサラが含まれています。" } ]
触ってみた所感
- 思ったよりも簡単に使える
- GPT-4oと同じくらい回答速度が速い(体感)
- ChatGPTと同じ感覚でプロンプト作ると、思ったような回答が得られなかったりするので、使いこなすには慣れが必要かもしれない
- レスポンスの形式をJSON形式で指定できるのは、プログラム上で扱う際にとても便利そう
まとめ
というわけで、GoogleのGemini APIを触ってみました。 今回はcurlコマンドでAPIを叩いてみましたが、様々な言語のライブラリも公開されているので、そのうちGemini APIを使ったアプリを作ってみたいですね。
採用情報
虎の穴ラボでは一緒に働く仲間を募集中です!
この記事を読んで、興味を持っていただけた方はぜひ弊社の採用情報をご覧ください。
toranoana-lab.co.jp
